linux unicode转中文(unicode转中文乱码)
在当今数字化世界中,我们经常遇到需要在不同操作系统和平台上进行字符编码转换的场景。尤其是对于Linux操作系统下的Unicode转中文,这一技术更是至关重要。Unicode作为一种国际化字符编码方案,拥有支持世界上几乎所有语言和字符的能力。而在Linux系统中,通过一系列的工具和 *** ,我们可以轻松地将Unicode字符转换为中文,实现文字的显示与输入的无缝交互。本文将介绍如何在Linux系统中进行Unicode转中文,为读者提供实用的技巧和 *** 。
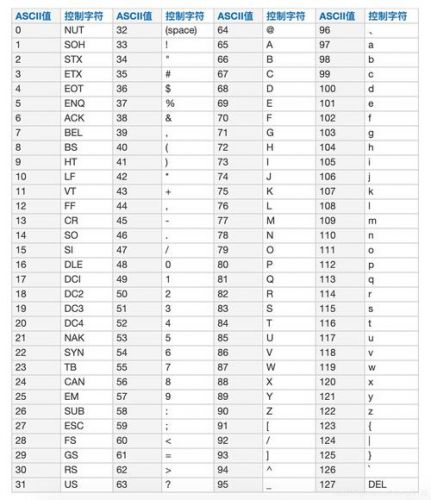
100财富给牛逼之人!就没人知道在linux下用c语言如何将汉字的unicode编码转化为汉字吗?
除了iconv命令,我们在linux系统下的man page的第三节还可以看到一组iconv函数。它们分别是
iconv_t iconv_open(const char *tocode, const char *fromcode);
size_ticonv(iconv_t cd, char **inbuf, size_t *inbytesleft, char **outbuf, size_t *outbytesleft);
int iconv_close(iconv_t cd);
iconv_open函数用来打开一个编码转换的流,iconv函数的作用是实际进行转换,iconv_close函数的作用就是关闭这个流。实际用法参见下面的例子,下面是一个将UTF-8码转换成GBK码的例子,我们假设已经有了一个uft8编码的输入缓冲区inbuf以及这个缓冲区的长度inlen。
iconv_t cd = iconv_open( "GBK", "UTF-8");
char *outbuf = (char *)malloc(inlen * 4 );
bzero( outbuf, inlen * 4);
char *in = inbuf;
char *out = outbuf;
size_t outlen = inlen *4;
iconv(cd, &in, (size_t *)&inlen, &out,&outlen);
outlen = strlen(outbuf);
printf("%s\n",outbuf);
free(outbuf);
iconv_close(cd);
试试这个四个函数,C 里面的,Linux 可用:
mbtowc
wctomb
mbstowcs
wcstombs
在 Linux 下试试看吧:
#include
#include#includeint main(void){size_t cch;char psz[1024];wchar_t pwsz[] = { 0x52B3, 0x788C, 0x788C, 0 };setlocale(LC_ALL, "");cch = wcstombs(psz, pwsz, 1024);if (cch != 0 && cch != -1) {printf("%s", psz);}return 0;}zdl_361 说的 "utf8 劳碌碌" 不对,因为我也输出 "劳碌碌",而我是用 Unicode 编码的。在 Windows 上,char 是 ANSI,Unicode (wchar_t) 是 UTF-16;在 Linux 上,char 是 UTF-8,Unicode (wchar_t) 是 UTF-32。不过对于这个函数来说,在哪个平台上都不会因为字符编码而影响使用。我得知道这是什么编码。utf8?解读完是乱码。52B3788C788C你从哪里复制的?
linux怎么设置成中文?
linux要修改语言环境为中文,可以打开系统首选项,在系统设置的语言项上选择中文。
*** /步骤
1/5
点击首选项
点击开始菜单上的首选项。
2/5
点击系统设置
点击首选项页面上的系统设置。
3/5
点击语言
点击右边的语言选项。
4/5
点击窗口上的语言
在弹出的窗口上点击语言选项。
5/5
选择中文
选择中文选项就可以了。
















